
Стандартное отклонение и стандартная ошибка
Вступление
стандарт D (SD) а также S tandard Е rror (SE) по-видимому, аналогичные терминологии; однако они концептуально настолько разнообразны, что они используются почти взаимозаменяемо в статистической литературе. Каждому термину обычно предшествует символ плюс-минус (+/-), который указывает на то, что они определяют симметричное значение или представляют диапазон значений. Неизменно оба выражения появляются со средним (средним) набором измеренных значений.
Интересно, что SE не имеет ничего общего со стандартами, с ошибками или с сообщением научных данных.
Подробный взгляд на происхождение и объяснение SD и SE покажет, почему профессиональные статистики и те, кто использует это сдержанно, оба склонны ошибаться.
Стандартное отклонение (SD)
SD является описательный статистика, описывающая распространение распределения. Как метрика, это полезно, когда данные обычно распределяются. Однако это менее полезно, когда данные сильно искажены или бимодальны, потому что они не очень хорошо описывают форму распределения. Как правило, мы используем SD при представлении характеристик образца, поскольку мы намерены описывать насколько данные изменяются по среднему значению. Другая полезная статистика для описания распространения данных - это межквартильный диапазон, 25-й и 75-й процентили и диапазон данных.
Разница заключается в описательный статистика также, и она определяется как квадрат стандартного отклонения. Обычно это не сообщается при описании результатов, но это более математически приемлемая формула (a.k.a. сумма квадратов отклонений) и играет роль в вычислении статистики.
Например, если у нас есть две статистики п & Q с известными отклонениями вар (П) & вар (Q) , то дисперсия суммы Р + Q равна сумме дисперсий: вар (P) + вар (Q) , Теперь очевидно, почему статистикам нравится говорить об отклонениях.
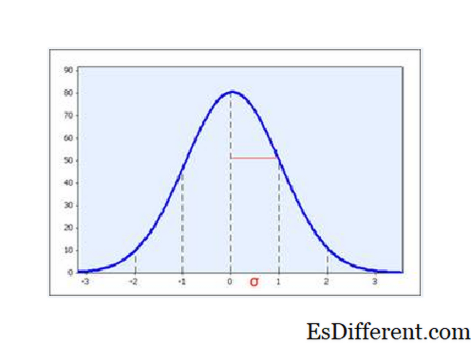
Но стандартные отклонения имеют важное значение для распространения, особенно когда данные обычно распределяются: среднее значение интервала +/- 1 SD можно ожидать захвата 2/3 образца, а среднее значение интервала + - 2 SD можно ожидать захвата 95% образца.
SD дает представление о том, насколько индивидуальные ответы на вопрос меняются или «отклоняются» от среднего. SD рассказывает исследователю, насколько распространены ответы: сосредоточены ли они вокруг среднего или разбросаны по всему миру? Все ваши респонденты оценили ваш продукт в середине шкалы, или кто-то одобрил его, а некоторые отклонили его?
Рассмотрим эксперимент, в котором респондентам предлагается оценивать продукт по ряду атрибутов по 5-балльной шкале. Среднее значение для группы из десяти респондентов (обозначаемое «A» через «J» ниже) для «хорошей стоимости за деньги» составляло 3,2 с SD 0,4, а среднее значение для «надежности продукта» составляло 3,4 с SD 2,1.
На первый взгляд (смотря только на средства), казалось бы, надежность была оценена выше стоимости. Но более высокий SD для надежности может указывать (как показано ниже в распределении), что ответы были очень поляризованы, где большинство респондентов не имели проблем с надежностью (с оценкой атрибута «5»), но меньший, но важный сегмент респондентов, проблема надежности и оценили атрибут «1». Однако, глядя на среднее значение, он говорит только часть истории, однако чаще всего это то, на что ориентируются исследователи. Распределение ответов важно учитывать, и SD обеспечивает ценную описательную меру этого.
| ответчик | Хорошая ценность для денег | Надежность продукта |
| 3 | 1 | |
| В | 3 | 1 |
| С | 3 | 1 |
| D | 3 | 1 |
| Е | 4 | 5 |
| F | 4 | 5 |
| г | 3 | 5 |
| ЧАС | 3 | 5 |
| я | 3 | 5 |
| J | 3 | 5 |
| Имею в виду | 3.2 | 3.4 |
| Std. Девиация | 0.4 | 2.1 |
Первый опрос: респонденты оценивают продукт по пятибалльной шкале
Два очень разных распределения ответов на 5-балльную рейтинговую шкалу могут дать одно и то же значение. Рассмотрим следующий пример, показывающий значения ответа для двух разных оценок.
В первом примере (Рейтинг «A») SD равен нулю, потому что ВСЕ ответы были точно средним значением. Индивидуальные ответы не отклонялись от среднего.
В рейтинге «B», хотя среднее значение группы одинаково (3.0) в качестве первого распределения, стандартное отклонение выше. Стандартное отклонение 1.15 показывает, что индивидуальные ответы в среднем * были чуть более 1 балла от среднего.
| ответчик | Рейтинг "A" | Рейтинг "B" |
| 3 | 1 | |
| В | 3 | 2 |
| С | 3 | 2 |
| D | 3 | 3 |
| Е | 3 | 3 |
| F | 3 | 3 |
| г | 3 | 3 |
| ЧАС | 3 | 4 |
| я | 3 | 4 |
| J | 3 | 5 |
| Имею в виду | 3.0 | 3.0 |
| Std. Девиация | 0.00 | 1.15 |
Второй опрос: респонденты оценивают продукт по пятибалльной шкале
Другой способ взглянуть на SD - это построить распределение как гистограмму ответов. Распределение с низким SD будет отображаться как высокая узкая форма, в то время как большая SD будет обозначаться более широкой формой.
SD обычно не указывает «правильно или неправильно» или «лучше или хуже» - более низкая SD не обязательно более желательна. Он используется исключительно как описательная статистика. Он описывает распределение по отношению к среднему.
T echnical disclaimer, относящийся к SD
Думая о том, что SD как «отклонение» - это отличный способ концептуально понять его смысл. Тем не менее, он фактически не рассчитывается как среднее (если бы это было так, мы бы назвали это «отклонениями»). Вместо этого он «стандартизирован» - несколько сложный метод вычисления значения с использованием суммы квадратов.
Для практических целей вычисление не имеет значения. Большинство программ табуляции, электронных таблиц или других инструментов управления данными будут вычислять SD для вас. Более важно понять, что передает статистика.
Стандартная ошибка
Стандартная ошибка - это выведенный статистика, которая используется при сравнении выборочных средств (средних) по группам населения. Это мера точность от среднего значения выборки. Среднее значение выборки - это статистическая информация, полученная из данных, имеющих базовое распределение. Мы не можем визуализировать его так же, как и данные, поскольку мы выполнили один эксперимент и имеем только одно значение. Статистическая теория говорит нам о том, что среднее значение выборки (для большого, более выбранного образца и в нескольких условиях регулярности) приблизительно нормально распределено. Стандартное отклонение этого нормального распределения - это то, что мы называем стандартной ошибкой.

Когда мы хотим сравнить средства исходов от эксперимента с двумя образцами Лечения A против лечения B, нам нужно оценить, насколько точно мы измерили средства.
На самом деле нас интересует, насколько точно мы измерили разницу между этими двумя средствами. Мы называем эту меру стандартной ошибкой разности. Вы не можете быть удивлены, узнав, что стандартная ошибка разницы в средствах выборки является функцией стандартных ошибок средств:

 , где n - количество точек данных.
, где n - количество точек данных.
Обратите внимание, что стандартная ошибка зависит от двух компонентов: стандартного отклонения выборки и размера выборки N , Это делает интуитивный смысл: чем больше стандартное отклонение выборки, тем менее точным может быть наша оценка истинного среднего.
Кроме того, большой размер выборки, чем больше информации мы имеем о населении, тем точнее мы можем оценить истинное значение.
SE является показателем надежности среднего значения. Небольшой SE является показателем того, что среднее значение выборки является более точным отражением фактического значения популяции. Более большой размер выборки обычно приводит к меньшему SE (тогда как SD не зависит напрямую от размера выборки).
Большинство исследовательских исследований включает в себя выборку из населения. Затем мы делаем выводы о популяции из результатов, полученных из этого образца. Если был сделан второй образец, результаты, вероятно, были бы точно совпадают с первым образцом. Если среднее значение для атрибута рейтинга составляло 3,2 для одного образца, это может быть 3,4 для второго образца того же размера. Если бы мы собирали бесконечное количество выборок (равного размера) из нашей популяции, мы могли бы отображать наблюдаемые средства как распределение. Затем мы могли бы вычислить среднее значение всех наших образцов. Это означало бы равное истинное значение популяции. Мы также можем рассчитать SD распределения средств выборки. SD этого распределения средств выборки является SE каждого отдельного образца.
Таким образом, мы имеем самое значительное наблюдение: SE является SD среднего значения.
| Образец | Имею в виду |
| первый | 3.2 |
| второй | 3.4 |
| третий | 3.3 |
| четвёртая | 3.2 |
| пятые | 3.1 |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| …. | …. |
| Имею в виду | 3.3 |
| Std. Девиация | 0.13 |
Таблица, иллюстрирующая взаимосвязь между SD и SE
Теперь ясно, что если SD этого распределения помогает нам понять, насколько далека среднее значение выборки от истинной совокупности, то мы можем использовать это, чтобы понять, насколько точна какая-либо индивидуальная выборка по отношению к истинному среднему значению. В этом суть SE.
На самом деле, мы набрали только один образец из нашего населения, но мы можем использовать этот результат для оценки надежности нашего наблюдаемого образца.
На самом деле, SE говорит нам, что мы можем быть на 95% уверены, что наше наблюдаемое среднее значение выборки плюс или минус примерно 2 (на самом деле 1,96). Стандартные ошибки от населения.
В приведенной ниже таблице показано распределение ответов от нашей первой (и единственной) выборки, используемой для наших исследований. SE 0,13, будучи относительно небольшим, дает нам указание на то, что наше среднее значение относительно близко к истинному среднему для нашей общей популяции. Предел погрешности (с доверием 95%) для нашего среднего значения (примерно) в два раза превышает это значение (+/- 0,26), сообщая нам, что истинное среднее значение, скорее всего, составляет от 2,94 до 3,46.
| ответчик | Рейтинг |
| 3 | |
| В | 3 |
| С | 3 |
| D | 3 |
| Е | 4 |
| F | 4 |
| г | 3 |
| ЧАС | 3 |
| я | 3 |
| J | 3 |
| Имею в виду | 3.2 |
| Std. заблуждаться | 0.13 |
Резюме
Многие исследователи не понимают различия между стандартным отклонением и стандартной ошибкой, хотя они обычно включаются в анализ данных. Хотя фактические расчеты для стандартного отклонения и стандартной ошибки выглядят очень схожими, они представляют собой две очень разные, но взаимодополняющие меры. SD рассказывает нам о форме нашего распределения, насколько близки значения отдельных данных от среднего значения. SE рассказывает нам, насколько близка наша выборка к истинному средству общей популяции.Вместе они помогают обеспечить более полную картину, чем может сказать нам только одно значащее.


